
-

- 随机文章

headfirst设计模式pdf高清无水印|百度网盘下载
编者注:headfirst design pattern pdf
Eric Freeman 的 HeadFirst 设计模式(中文版); El Elisabeth Freeman 是一位作家、讲师和技术顾问。共14章,每章介绍几种设计模式,完全涵盖了四人版的全部23种设计模式。小编为大家准备了本书的PDF版本,内容非常高清,快来下载吧

书籍介绍
《Head First Design Patterns (Chinese Version)》编者推荐:强大的写作阵容。 《Head First Design Patterns(中文版)》作者 Eric Freeman; El Elisabeth Freeman 是一位作家、讲师和技术顾问。 Eric 拥有耶鲁大学计算机科学博士学位,
E1isabath 拥有耶鲁大学计算机科学硕士学位。 Kathy Sierra FHBert Bates 是畅销书 HeadFirst 系列丛书的作者,也是 Sun Java 开发人员认证考试的开发人员。 《Head First Design Patterns(中文版)》产品设计的应用神经生物学,
认知科学,以及学习理论,让这本书深深地印在你的脑海里,不容易忘记。 《Head First Design Patterns(中文版)》的写作方式采用引导式教学,不直接告诉你做什么,而是用故事作为介绍,
让读者思考并找到解决问题的方法。在解决问题的过程中,会出现一些新的问题,然后继续思考和解决问题,可以加深体验。作者以大量的人生故事为背景,比如第一章的鸭子,
第 2 章是气象站,第 3 章是咖啡店,而且书中的插图(几乎每一页)都充满了插图,因此阅读起来既生动有趣又不会感到昏昏欲睡。作者还使用了倾斜的手写字体来增加“存在感”
。许多搞笑的对话都经过精心设计,让学习过程不会太无聊。还有一个模式告白程序,将设计模式拟人化成节目嘉宾,畅所欲言。 《Head First Design Patterns(中文版)》
大量使用uML的类图(Static Structure Diagram)。虽然书中的示例程序都是用Java编写的,但《Head First Design Patterns(中文版)》中介绍的内容适用于任何00语言的用户。
包括c++和c子。每章都有不同数量的测验问题。每章末尾都有一页整理要点,也是精髓。我总是使用此页面进行审查。 Head First 设计模式(中文版)
内容: 1. 设计模式介绍 欢迎来到设计模式的世界 2. 观察者模式让您的对象了解情况 3. 装饰器模式来装饰对象 4. 工厂模式来烘托 OO 的精华 5. 单例模式独特的对象
6 命令模式封装调用 7 适配器模式和外观模式 随机遭遇模式 8 模板方法模式封装算法 9 选择器和组合模式 管理良好的集合 10 状态模式 事物状态 11 代理模式控制对象访问 12 复合模式模式模型 13与现实世界中的设计模式模式相处
Head First 设计模式的类型
23种设计模式介绍
一般来说,设计模式分为三类:
创建模式有五种类型:工厂方法模式、抽象工厂模式、单例模式、构建器模式、原型模式。
有七种结构模式:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式和享元模式。
共十一种行为模式:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式
相关内容图片预览








Head First 设计模式:迭代器模式
迭代器模式
由于本章涉及两种模式,内容有点过多,下一篇有组合模式。
有很多方法可以将对象堆叠到一个集合中。您可以将它们放入数组、堆栈、列表或哈希表中,这是您的自由。每个都有自己的优点和合适的用例,但是总有一段时间你的客户想要迭代这些对象,当他这样做时,你会让客户看到你的实现吗?我们当然希望最好不要这样做!这太不专业了。本章中的迭代器模式将允许客户端迭代您的对象,而无需窥探您如何存储它们。
我们来看看迭代器模式的定义:
提供一种顺序访问聚合对象的元素而不暴露其内部表示的方法。
示例:有两家餐厅,一家披萨店和一家煎饼店。它们被合并。虽然可以同时使用煎饼屋的早餐和餐厅的午餐,但是煎饼屋的菜单使用一个ArrayList来记录菜单。 ,而餐厅使用数组,并且两家餐厅都不愿意修改它们的实现。毕竟有很多代码依赖于它们。
还好他们都实现了MenuItem:
//菜单项,保存菜单信息 public class MenuItem { private String name;私有字符串描述;私人布尔素食主义者;私人双倍价格;公共菜单项(字符串名称,字符串描述,布尔素食,双倍价格){ super( ); this.name = 名称; this.description = 描述; this.vegetarian = 素食主义者; this.price = 价格; } } public String getName() { 返回名称; } } public void setName(String name) { this.name = name ; } public String getDescription() { 返回描述; } } public void setDescription(String description) { this.description = description; ; } } public double getPrice() { } 返回价格; } } public void setPrice(double price) { this.price = price; }}
我们来看看两家店各自菜单的实现:
煎饼店:使用ArrayList
// 煎饼餐厅对象,它使用ArrayList 来保存菜单。公共类 PancakeHouseMenu { ArrayList
披萨:使用数组
// 比萨餐厅对象,使用数组保存菜单信息。公共类 PizzaHouseMenu { 静态最终 int MAX_ITEMS = 2; int numberOfItems = 0;菜单项[] 菜单项; public PizzaHouseMenu() { menuItems = new MenuItem[MAX_ITEMS]; } } public void addItem(字符串名称,字符串描述,布尔素食,双倍价格){ MenuItem menu = new MenuItem(名称,描述,素食,价格); if (numberOfItems >= MAX_ITEMS) System.out.println("对不起,菜单数已满"); MenuItem[] getMenuItems() { 返回 menuItems; }}
有两种不同的菜单表示有什么问题?
假设你是一名女服务员。这就是你所做的,你会怎么做?
打印菜单();打印出菜单上的每个项目
printBreakfastMenu();只打印早餐
printLunchMenu();只打印午餐
printVegetarianMenu();打印所有素食菜单
isItemVegetarian(名称);查询指定菜品是否素食
指定项目的名称,如果项目是素食返回true,否则返回false
要打印菜单上的所有项目,您必须调用 PancakeHouseMenu 和 PizzaHouseMenu 的 getMenuItenm() 方法来获取它们各自的菜单项。两者的返回类型不同。
PancakeHouseMenu pancakeHouseMenu=new PancakeHouseMenu();ArrayList breakfastItems=pancakeHouseMenu.getMenuItems(); PizzaHouseMenu PizzaHouseMenu=new PizzaHouseMenu();MenuIten[] linchItenms=pizzaHouseMenu.getMenuItens();
打印菜单需要的数组和集合,并使用循环将数据一一列出
public class Client { public static void main(String[] args) { // 首先获取煎饼餐厅的菜单集合 PancakeHouseMenu pancakeHouseMenu = new PancakeHouseMenu(); ArrayList
我们总是需要处理这两个菜单的遍历,如果有第三家餐厅以不同的方式实现菜单集合,我们就需要有第三个循环。
我可以封装遍历吗?
可以封装更改。显然,这里改变的是不同集合类型引起的遍历。但这可以封装吗?让我们来看看这个想法......
为了方便煎饼餐厅,我们需要用到ArrayList的size()和get()方法;
为了方便披萨餐厅,我们需要使用数组的长度字段,并在方括号中输入索引;
现在我们创建一个对象,称之为迭代器(Iterator),用它来封装“遍历集合中每个对象的过程”;
要给餐厅菜单添加一个迭代器,我们需要先定义迭代器接口,然后为披萨餐厅创建一个迭代器类:
public interface Iterator { boolean hasNext(); Object next();}public class PizzaIterator implements Iterator { MenuItem[] items;整数位置 = 0; public PizzaIterator(MenuItem[] items) { this.items = items; } // 判断数组的下一个索引是否有元素 public boolean hasNext() { if(position >= items.length || items[position] == null) return false;否则返回真; // 获取当前索引位置元素 public Object next() { MenuItem item = items[position++];归还物品; }} 公共类 PancakeIterator 实现迭代器 { ArrayList
创建迭代器后,重写比萨餐厅的代码,创建一个PizzaMenuIterator并返回给客户端:
public class PizzaHouseMenu { static final int MAX_ITEMS = 2; int numberOfItems = 0;菜单项[] 菜单项;公共 PizzaHouseMenu() { menuItems = new MenuItem[MAX_ITEMS]; addItem("1 号披萨", "素食披萨", true, 4.99); addItem("2 号披萨", "海鲜蛤蜊披萨", true, 5.99); } } public void addItem(字符串名称,字符串描述,布尔素食,双倍价格){ MenuItem menu = new MenuItem(名称,描述,素食,价格); if (numberOfItems >= MAX_ITEMS) System.out.println("对不起,菜单数已满");否则 PizzaIterator menuItems[numberOfItems++] = menu; ); }} 公共类 PancakeHouseMenu { ArrayList
我们不再需要 getMenuItems() 方法,而是使用 createIterator() 方法从菜单项数组创建迭代器并将其返回给客户端,返回迭代器接口。客户端不需要知道餐厅菜单是如何实现和维护的,也不需要知道迭代器是如何实现的。客户端可以简单地使用这个迭代器直接迭代菜单。修改客户端类的调用如下:
public class Waitress { PancakeHouseMenu pancake; PizzaHouseMenu 披萨;公共女服务员(PancakeHouseMenu 煎饼,PizzaHouseMenu 比萨饼){ this.pancake = pancake; this.pizza = 比萨饼; ; printMenu(pizzaIterator);迭代器 pancakeIterator = pancake.createIterator(); printMenu(pancakeIterator); } } private void printMenu(Iterator iterator) { while(iterator.hasNext()) { .MenuItem menu = (MenuItem) it System.out.print(menu.getName() + ",Price:"); System.out.print(menu.getPrice() + ","); System.out.print(menu.getDescription() + "\n"); } } }} public class Client { public static void main(String[] args) { PancakeHouseMenu pancake = new PancakeHouseMenu(); PizzaHouseMenu 披萨 = 新 PizzaHouseMenu();女服务员 waitress = new Waitress(pancake, Pizza);服务员 .print Menu(); }}
输出结果:

到目前为止,我们已经将客户调用与餐厅的菜单数据接口解耦,客户调用不再需要为每个具有不同数据结构的菜单编写一组遍历代码。
到目前为止,我们做了什么?
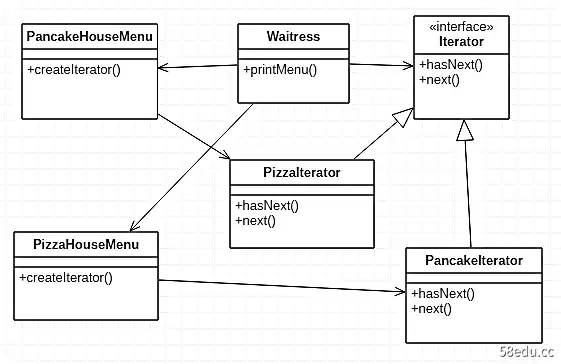
我们现在使用一个通用的迭代器接口 (Iteraotr) 来实现两个具体的类(PizzaIterator 和 PancakeIterator)。这两个具体类都实现了自己的 hasNext() 和 next() 方法。
在 PancakeHouseMenu 和 PizzaHouseMenu 类中,创建一个 createIterator() 方法来返回它们各自的迭代器,并在 Waitress 类中,使用两个餐厅对象返回的迭代器来打印菜单。这时,Waitress 类和Client 类不再需要关心存储菜单的数据结构,而只关心从迭代器中获取菜单。
迭代器模式为您提供了一种顺序访问聚合对象的元素的方法,而无需知道它在内部是如何表示的。您已经在前两个菜单实现中看到了这一点。在设计中使用迭代器的影响是显而易见的:如果你有一个统一的方法来访问聚合中的每个对象,你可以编写多态代码来处理这些聚合,使用与以前相同的 printMenu() 方法,只要有是一个迭代器,这个方法不关心菜单是用数组还是集合或其他数据结构存储的。
对您的设计的另一个重要影响是迭代器模式将在元素之间导航的责任转移到迭代器而不是聚合对象。这不仅使聚合的接口和实现更加简洁,而且可以让聚合更多地关注它应该关注的事情,而不是遍历事情。
让我们检查一下类图,并在未来将它拼凑起来......

先看Aggregate接口,有一个通用接口,提供所有聚合使用,非常方便客户端代码,将客户端代码与聚合对象的实现解耦。
让我们看一下 ConcreteAggregate 类。这个具体的聚合包含一个对象集合并实现了一个返回集合迭代器的方法。每个具体聚合负责实例化一个具体迭代器,辅助迭代器促进对象的集合。
接下来是迭代器接口。这是所有迭代器都必须实现的接口。它包含允许您在集合元素之间移动的方法。您可以自己设计或使用 java.util.Iterator 接口。
最后,有一个特定的迭代器,负责遍历集合。
单一职责
如果我们允许聚合实现它们的内部集合以及相关的操作和遍历方法会怎样?我们已经知道这次增加了聚合中的方法数量,但那又如何呢?为什么这样做不好?
想知道为什么,第一选择需要认清,当我们让一个类不仅做自己的事,还要承担更多的责任时,我们给这个类两个改变的理由。如果集合改变了,类也必须改变,如果我们遍历的方式改变了,类也必须改变。所以,这就引出了设计原则的核心:
单一职责:一个类只有一个改变的原因。
一个类的每个职责都有一个潜在的变化领域。不止一项责任意味着不止一个领域的变化。这个原则告诉我们要尽量让每个类都有一个单一的职责。
您可能听说过凝聚力这个词,它用于衡量一个类或模块服务于单一目的或职责的紧密程度。
当一个模块或一个类被设计成只支持一组相关的功能时,我们说它具有高内聚性;相反,当它被设计为支持一组不相关的功能时,我们说它具有低内聚性。
凝聚力是一个比单一职责更笼统的概念,但两者实际上是非常密切相关的。与承担许多责任的低内聚集群相比,遵守这一原则的类更有可能具有高内聚性并且更易于维护。
这些是迭代器模式的一些内容。